pag 89 - La
moltiplicazione
|
LA MOLTIPLICAZIONE HARDWARE
Tutti i processori della serie PIC18 hanno nell' ALU un
moltiplicatore hardware, in grado di moltiplicare tra di loro due numeri da
8 bit ciascuno.
Il risultato, a 16 bit, viene immagazzinato in due registri appositi, PRODH
e PRODL.
L' operazione è eseguita dall' istruzione MULWF (MULtiply
W register with File), con la sintassi seguente :
mulwf f[,a] ; (w) * (f) -> (PRODH)(PRODL)
Esiste anche l' istruzione MULLW (MULtiply Literal
with W)
mulwf k ; (w) * (k) -> (PRODH)(PRODL)
con k variabile da 0 a 255 . In entrambi i casi si
tratta di operazioni senza segno (unsigned).
Queste istruzioni di moltiplicazione non modificano il contenuto dello
STATUS.
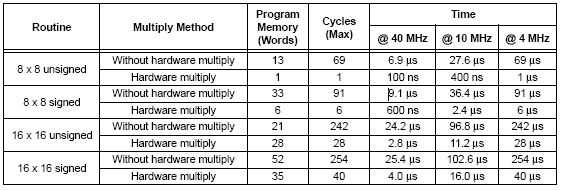
Il vantaggio della moltiplicazione hardware è il fatto che
l' operazione viene eseguita da una sola istruzione in un solo ciclo,
riducendo le dimensioni del sorgente ed il tempo di esecuzione. Ad esempio,
una moltiplicazione 8 x 8 via software richiederebbe almeno 13 istruzioni,
per un totale di 69 cicli macchina; a 10MHz di clock, si spenderebbero circa
27 micro secondi, mentre con il moltiplicatore hardware occorrono soltanto
400 nano secondi !
La tab. 8-1 da una idea di queste grandezze:
Dal punto di vista del codice, una semplice moltiplicazione
8 x 8 senza segno è, quindi, eseguita in due righe :
|
; multiply (unsigned)
ARG1 x ARG2
movf ARG1, W
mulwf ARG2 |
Nel caso di moltiplicazione con segno (signed) occorrerà
tenere conto del bit di segno (MSB):
|
; multiply (signed) ARG1 x ARG2
movf ARG1,
W
mulwf ARG2
btfsc ARG2, SB
; test sign bit
subwf PRODH,
f ; y , PRODH-ARG1
movwf ARG2, W
btfsc ARG1, SB
; test sign bit
subwf PRODH,F
; y, PRODH - ARG2 |
La documentazione di Microchip da' pure esempi di
moltiplicazioni a 16 bit unsigned e signed.
Diamo qui un esempio di algoritmo per la moltiplacazione
unsigned 16 x 16 bit
Moltiplicare due numeri a 16 bit AARG1H:L e AARG2H:L
-
Calcolare il prodotto parziale AARG1L * AARG2L e
salvarlo nella locazione Res:+1.
-
Calcolare il prodotto parziale di AARG1H*AARG2H e
salvarlo nella locazione Res+2:+3.
-
Calcolare il prodotto parziale di AARG1H*AARG2L e
sommarlo a Res+1:+2.
Il carry va considerato per la somma successiva
-
Sommare il carry a Res+3.
-
Calcolare il prodotto parziale AARG1L*AARG2H e sommarlo
a Res+1:+2.
Il carry va considerato per la somma successiva.
-
Sommare il carry a Res+3
|
;
assegnazioni memoria
; AARG1L
; AARG1H
; AARG2L
; AARG2H
; Res:4
MUL16
movf AARG2H,W
mulwf AARG1H ; calcola AARG2H × AARG1H
movff PRODL, Prod+2
movff PRODH, Prod+3
movf AARG2L, W ; calcola AARG2L × AARG1L
mulwf AARG1L
movff PRODL, Prod
movff PRODH, Prod+1
movf AARG2L, W
mulwf AARG1H ; calcola AARG2L * AARG1H
movf PRODL, W ; somma AARG2L * AARG1H a Res
addwf Prod+1, F
movf PRODH, W
addwfc Prod+2, F
movlw 0
addwfc Prod+3, F ; somma carry
movf AARG2H, W
mulwf AARG1L ; calcola AARG2H * AARG1L
movf PRODL, W ; somma AARG2H * AARG1L a Res
addwf Prod+1, F
movf PRODH, W
addwfc Prod+2, F
movlw 0
addwfc Prod+3, F ; somma carry
return |
Qui
trovate un progetto per MPLAB con il test dell' algoritmo.
Moltiplicazioni a più bytes potranno essere sviluppate con
tecniche analoghe.
Ad esempio, ecco una moltiplicazione 24 * 16
|
MUL24X16 ;
AARG <-- AARG * BARG
movff AARG2, TEMP
movff AARG2, WREG
mulwf BARG1
movff PRODH, AARG3
movff PRODL, AARG4
movff AARG1, WREG
mulwf BARG0
movff PRODH, AARG1
movff PRODL, AARG2
mulwf BARG1
movff PRODL, WREG
addwf AARG3, F
movff PRODH, WREG
addwfc AARG2, F
clrf WREG
addwfc AARG1, F
movff TEMP, WREG
mulwf BARG0
movff PRODL, WREG
addwf AARG3, F
movff PRODH, WREG
addwfc AARG2, F
clrf WREG
addwfc AARG1, F
movff AARG0, WREG
mulwf BARG1
movff PRODL, WREG
addwf AARG2, F
movff PRODH, WREG
addwfc AARG1, F
movff AARG0, WREG
mulwf BARG0
clrf AARG0
clrf WREG
addwfc AARG0, F
movff PRODL, WREG
addwf AARG1, F
movff PRODH, WREG
addwfc AARG0, F
return |

NOTA:
Un particolare interessante è che i due registri di risultato
della moltiplicazione hardware PRODH e PRODL sono
leggibili e scrivibili in modo del tutto indipendente dalle
istruzioni di moltiplicazione e quindi possono essere utilizzati
come due generiche locazioni di memoria RAM.
Ovviamente è necessario che, nel momento in cui si utilizzano
PRODH:L per usi generici, essi non siamo impegnati dalle istruzioni
di moltiplicazione.
|
|
|
|
Copyright © afg. Tutti i diritti riservati.
Aggiornato il 07/12/10.
|