Routine di attesa o ritardo (delay)
waste time
|
La gestione di eventi di tempo (temporizzazioni,
pause, attese, ritardi, pulse stretching, debounce, ecc) sono realizzabili in
molti modi.
Il più semplice è quello che gli anglofoni chiamano "waste
time", letteralmente "tempo nella spazzatura", "tempo
perso".
Si tratta essenzialmente di questo: sappiamo che ogni istruzione del
processore richiede un certo tempo di esecuzione (ciclo istruzione) che dipende
dalla velocità del clock.
Ora, se facciamo eseguire al programma una serie di istruzioni, esse
impiegheranno un certo tempo ben determinato per essere completate.
Il waste time si basa dunque sull' utilizzare esclusivamente il
set di istruzioni del processore e ripetere un numero sufficiente di volte una o
più di esse fino ad ottenere il tempo richiesto.
La loro struttura è estremamente semplice, ma non per questo poco precisa o
poco efficace, anche se non è pensabile di utilizzare questo metodo con
vantaggio in tutte le possibili situazioni.
Infatti si tratta di strutture "polling"
e "locked":
- polling indica una struttura che non fa uso dell' interrupt per determinare
uno specifico avvenimento
- locked indica una struttura in cui, una volta entrati, non è possibile uscire
fino a che essa ha completato la sua funzione.
E ci sono per questo vantaggi e svantaggi. I
vantaggi sono:
- molto semplici da implementare
- non utilizzano alcuna risorsa particolare del processore (timer o altro), ma
solo istruzioni del set
- possono essere estremamente precisi (errore 0%) e calcolabili
- sono portabili tra i processori della stessa famiglia senza alcuna modifica (o
modifiche minimali se non scritte in modo corretto)
Gli svantaggi sono:
- sono polling e locked: il processore è impegnato nell'esecuzione della
temporizzazione e non può fare altre operazioni (da qui il nome waste time)
- quanto più è elevata la richiesta di tempo rispetto al tempo di ciclo del
processore, tante maggiori risorse si memoria RAM saranno necessarie alla
procedura
- possono occupare, se non ottimizzate, un buon volume di memoria programma
In sostanza, con un esempio, è come se, aspettando che il caffè bolla,
passiamo il tempo girandoci i pollici. In alcune situazioni è ammissibile, ad
esempio quando non ho altro da fare. Nelle situazioni in cui, invece, ho altri
impegni contemporanei si dovrà adottare una gestione in interrupt, ad esempio
facendo uso di un timer
Detto questo, vediamo di chiarire di più come
funziona il metodo.
Come funziona un waste time
Il tempo è un elemento fondamentale di ogni
cosa. Nella musica, metro-misura, durata, pausa, ritmo, sono gli elementi che
trasformano una sequenza di note di per se poco significative in una brano
eccelso.
Così pure nel controllo dei processori, elementi di temporizzazione, attesa,
ritardo, sono elementi della massima importanza per l' esatto controllo degli
ingressi e delle uscite.Ad esempio, nel lampeggio di un LED, il flow
chart richiede due elementi di tempo, due attese che permettono all' osservatore
di percepire il lampeggio.
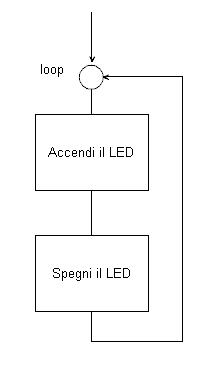 |
Infatti se realizzasi un ciclo di questo genere il
tempo in cui il LED è acceso o spento avrebbe la lunghezza del ciclo
dell' istruzione relativa, ovvero pochi micro secondi (o
meno), a seconda del clock del processore.
Il LED lampeggerebbe, certamente, ma ad una
frequenza tale da non poter esser percepita dall' occhio, che ha una
latenza dell' ordine di svariati milli secondi.
Occorrerà apportare una variazione fondamentale al
flow chart. |
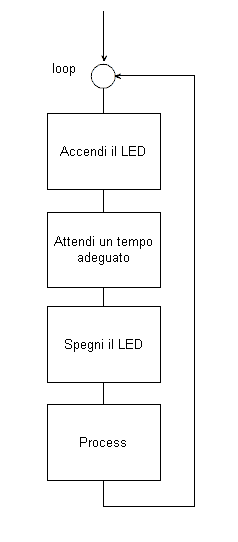 |
Questa variazione consiste nell' aggiungere due
momenti di attesa, uno a LED acceso ed uno a LED spento affinchè l'
occhio possa percepire la variazione della luminosità.
Ad esempio, inserendo una attesa di 0.25 s il LED si
accenderà e spegnerà 2 volte ogni secondo, in modo ben visibile.
Inoltre, avendo la possibilità di variare i
parametri dei due ciclo di attesa sarà possibile sia ottenere
qualunque altra frequenza dio lampeggio, sia ottenere tempi differenti
per lo stato di on e quello di off. |
Come ottenere queste attese ?
La via più semplice è la "perdita di
tempo", stare li ad aspettare un tot senza fare altro. E per fare aspettare
una macchina digitale, gli si da qualcosa da contare. Le forme più semplici di
"contare" sono quelle dette waste time.
Nelle tradizione dell' Europa orientale e del vicino oriente, chi era inseguito
da un vampiro aveva la possibilità di sfuggirgli gettando alle sue spalle
manciate di piccoli semi, pepe, sesamo e simili; il vampiro sarebbe stato
costretto a fermarsi e avrebbe potuto riprendere l' inseguimento solo dopo aver
contato tutti i semi, dando così modo alla vittima di salvarsi.
Analogamente a questo esempio, diamo al processore-vampiro da
"contare" un po' di bit e facciamo in modo che non prosegua il flusso
delle istruzioni fino a che non ha esaurito il conteggio.
Perchè questo ? semplicemente perchè:
- l' esecuzione di ogni istruzione è
completata in un tempo ben definito;
- e questo tempo dipende dal clock del
processore
Per inciso, più veloce è il clock (maggiore
frequenza), minore è il tempo di ciclo di una istruzione; e viceversa.
Questi tempi possono essere calcolati con
estrema precisione (errore 0%) e non dipendono dal programma, ma, in assoluto,
solamente dalla precisione del clock.
Nei PIC, che sono RISC, si è cercato di
uniformare il tempo di esecuzione delle istruzioni ad un solo ciclo, anche se ne
esistono diverse che richiedono due cicli.
Questo ciclo di istruzione vale 1/4 del clock principale, ovvero servono 4
impulsi del clock principale per completare una istruzione e fare avanzare il
program counter sulla successiva.
ciclo istruzione = clock
/ 4
Così, per 4 MHz di clock (250 ns), il clock delle istruzioni è 1 MHz e il
ciclo di una istruzione è di 1 us.
Con un clock a 20 MHz il ciclo di istruzione è 200 us.
Per cui, se devo ottenere un ritardo di 4 us
con clock a 4 MHz, basterà far eseguire 4 istruzioni da un ciclo ognuna.
Ovviamente queste istruzioni non devono fare nulla che alteri il resto del
programma. E per questo esiste l' istruzione
NOP
(no operation - nessuna
operazione) che "spreca" 1 ciclo.
; ritardo di 4 us @ 4 MHz
ritardo4
NOP ;
1 us
NOP
; + 1 us
NOP
; + 1 us
NOP
; + 1 us = 4 us |
In base a questo concetto, è possibile creare ritardi di qualsiasi durata, con
errore 0%, dipendente solamente dalla precisione del cristallo o dell'
oscillatore che determina la lunghezza del ciclo.
Questo sistema ha il vantaggio di essere estremamente semplice, non richiedere
documentazione perchè ovvio, scalabile a piacere, portabile su qualsiasi
processore (tutti, di qualsiasi genere, dispongono nel set di un
NOP).
Per contro, una cosa del genere è
evidentemente sensata solo per ripetizioni limitate.
Se si volessi ottenere con questo sistema 1 s di ritardo si dovrebbe usare
1000000 di
NOP, ognuno dei quali occupa una cella di memoria programma !
Servirebbe 1 MB di memoria programma solo per questo.
Certamente si può ricorrere a istruzioni più
"dispendiose" in fatto di tempo di esecuzione:
; ritardo di 4 us @ 4 MHz
ritardo4
GOTO ritardo2
; 2 us
ritardo2
GOTO fineritardo
; + 2 us = 4 us
fineritardo
; altre istruzioni del
programma |
dato che GOTO è una istruzione a due cicli.
Per ottenere ritardi dispari basta aggiungere un
NOP
:
; ritardo di 5 us @ 4 MHz
ritardo4
GOTO ritardo2
; 2 us
ritardo2
GOTO fineritardo
; + 2 us
fineritardo
NOP
; + 1 us = 5 us
; altre istruzioni del
programma |
Ma è evidente che anche questo sistema va bene per tempi molto limitati,
altrimenti si incorre nei problemi visti prima.
Altre soluzioni elaborate sono possibili
usando solo il set di istruzioni, ad esempio, chiamando una subroutine che non
contiene nulla se non l' istruzione di ritorno.
FOUR return ; ritardo di 4 cicli
[...]
ritardo4 call FOUR ; chiama la sub FOUR che ritorna dopo 4 cicli |
Rispetto alle precedenti, salva spazio e il return può essere la fine di un' altra qualsiasi subroutine, ma ha le stesse
possibilità limitate delle precedenti soluzioni, con in più il difetto di
impiegare uno livello di stack per la chiamata, con il rischio di overflow per i
processori più piccoli.
Per superare questo limite, basta implementare
delle strutture a loop.
|